【AIクイズ】ChatGPTが「いい感じ」に答えられる裏側の仕組み、知ってる?
更新日:
 イチオシスト
イチオシスト
ライター / 編集
イチオシ編集部 旬ニュース担当
注目の旬ニュースを編集部員が発信!「イチオシ」は株式会社オールアバウトが株式会社NTTドコモと共同で開設したレコメンドサイト。毎日トレンド情報をお届けしています。
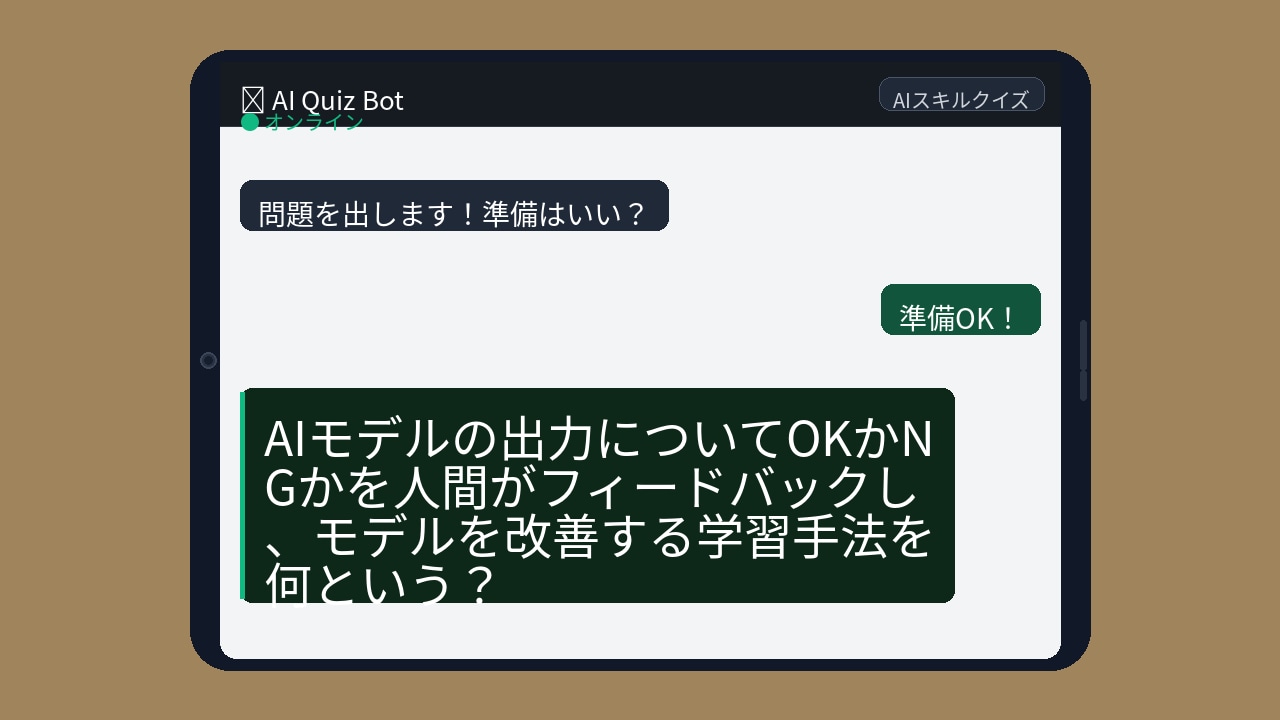
【問題】
AIが人間にとって自然で役立つ回答を返せるようになった背景には、ある画期的な学習手法があります。この手法なくして今のChatGPTは生まれなかったと言っても過言ではありません。
★ ヒント
人間が「この回答は良い」「この回答はダメ」と評価し、そのフィードバックをもとにAIを鍛えます。強化学習(Reinforcement Learning)の一種です。
【解説】
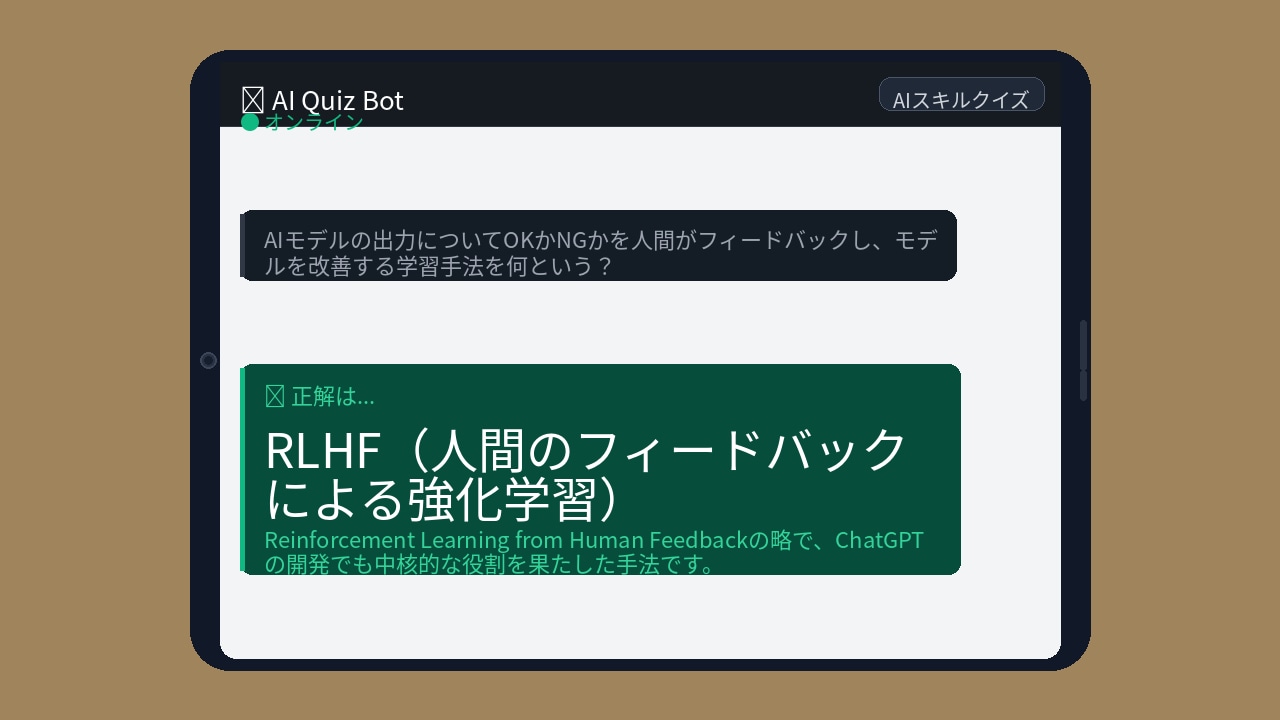
RLHFとは「Reinforcement Learning from Human Feedback」の略で、人間のフィードバックを使ってAIモデルを強化学習させる手法です。具体的には、AIが生成した複数の回答を人間が比較・評価し、より良い回答を学習させていきます。この手法によって、AIは単に文法的に正しいだけでなく、人間にとって有用で安全な回答を生成できるようになりました。OpenAIがChatGPTを開発する際にこのRLHFを大規模に採用したことで、一気に注目を集めました。現在ではGoogleのGeminiやAnthropicのClaudeなど、主要なAIモデルの多くがこの手法を活用しています。AIの「alignment(整合性)」を実現するための重要な技術として、AI業界では必須の知識となっています。
AIが賢く振る舞える裏には、人間の地道な評価作業があるんですね。次回もAIの知識をアップデートできるクイズをお届けします!
さらにもう一問!
▶ 【AIクイズ】AIを「野放し」にしてない?この仕組み知らないとヤバいかも
記事提供元:脳トレ日和
※記事内容は執筆時点のものです。最新の内容をご確認ください。